

🧊foril







🧊foril
KMP 字符串匹配算法
简单记录一下 KMP 算法的一些基本要点,免得自己总是一遍一遍忘记再找半天。
核心思想
KMP 最核心的想法就是在匹配到不一致的字符后,并不是移一位,从头开始重新比较,而是通过构建一个 “部分匹配表”,记录 匹配到当前字符后,前缀匹配到的长度(可以省略不比的长度),然后跳过匹配的前缀,以加快比较。因为在被匹配的字符串中,不需要任何回退的操作,这一部分的时间复杂度为 ,其中 为被匹配串的长度。同时为了构建部分匹配表,需要对匹配串进行预处理,时间复杂度为 ,其中 为匹配串的长度。所以整个算法的时间复杂度为 。
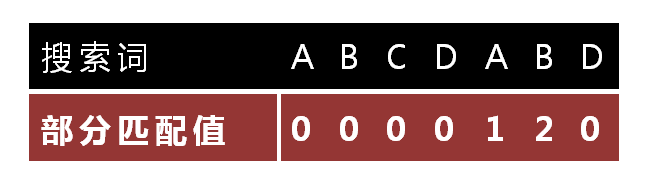
这里放一张阮一峰老师 博客 中的部分匹配表图片以帮助理解,假如匹配到最后一个字母 D 时匹配失败,最后一个匹配成功的字母 B 的部分匹配值为 2,也就是说前两个字母我们可以不用比较(因为被匹配的串开头前两个字母必为 AB),所以我们只需要移动 6-2=4 个字符即刻。
所有要与被匹配串匹配的字符串(称之为模式串),必须先自身匹配:对每个子字符串
[0...i],算出其 「相匹配的真前缀与真后缀中,最长的字符串的长度」。
算法实现
这里同时附上灵神的 讲解,以及 Python 代码。灵神讲解中有关建立部分匹配表时字母不匹配如何快速往回找的部分讲解非常清楚。
假如有模式串
abababzabababx对子字符串abababzababab来说,真前缀有a,ab,aba,abab,ababa,ababab,abababz, ...真后缀有b,ab,bab,abab,babab,ababab,zababab, ...所以子字符串abababzababab的真前缀和真后缀最大匹配了 6 个(ababab),那次大匹配了多少呢?
容易看出次大匹配了 4 个(abab),更仔细地观察可以发现,次大匹配必定在最大匹配ababab中,所以次大匹配数就是ababab的最大匹配数!按照这个理解,在构建自身匹配时,我们匹配到最后一个
b后的字母不是z而是x,那么我们需要找到比最前面的ababab更短的最大匹配数,那我们必然是从次大的匹配数开始找,也就是当前最大匹配 ababab 的最大匹配,所以我们找到了max_match_len[matched_pattern_tail] - 1,按这个方法,我们从 6 找到了 4,然后再找到 2,最后找到 0,得到x的最大匹配数为 0,所以需要从头开始匹配。
class Solution: def strStr(self, s: str, pattern: str) -> int: def cal_mml(pattern: str) -> List[int]: max_match_len = [0] * len(pattern) matched_pattern_tail = 0 for i in range(1, len(pattern)): while matched_pattern_tail > 0 and pattern[matched_pattern_tail] != pattern[i]: matched_pattern_tail = max_match_len[matched_pattern_tail - 1] if pattern[matched_pattern_tail] == pattern[i]: matched_pattern_tail += 1 max_match_len[i] = matched_pattern_tail return max_match_len max_match_len = cal_mml(pattern) # search matched_pattern_tail = 0 # 指向 pattern for i in range(len(s)): while matched_pattern_tail > 0 and s[i] != pattern[matched_pattern_tail]: matched_pattern_tail = max_match_len[matched_pattern_tail - 1] if s[i] == pattern[matched_pattern_tail]: matched_pattern_tail += 1 if matched_pattern_tail == len(pattern): return i + 1 - len(pattern) # 这里也可以根据需要,找到所有匹配的位置,而不是第一个 # res.append(i + 1 - len(pattern)) # matched_pattern_tail = max_match_len[matched_pattern_tail - 1] return -1