

🧊foril







🧊foril
基于 ALS 协同推荐算法的简易购物推荐练习
基于ALS协同推荐算法和SparkStreaming实时运算的的简易Kafka架构购物推荐练习。
基于ALS协同推荐算法的简易购物推荐练习
什么是ALS
ALS是交替最小二乘(Alternating Least Squares)的简称。
ALS属于数据挖掘,可以做推荐系统,比如电影推荐、商品推荐、广告推荐等。
原理就是给各个指标,判定等加权重,然后将这些训练集输入ALS,包括其他的参数,内部进行矩阵相乘,根据这些权重,给用户未点击的商品也给一个分数,就是喜好程度。然后把喜好程度高的商品推荐给用户,假如用户不喜欢,从线上观察效果不好,那这个模型就有问题,需要修改参数,修改权重,或者添加权重,使之达到一个理想的效果!
本项目做一个简易的基于ALS协同推荐算法的简易购物推荐练习,在只知道用户评分矩阵(即对于不同商品的评分)的情况下,向用户推荐商品。
主要目的在于完成大作业 scala 的学习、MLlib的学习使用、sparkStreaming的学习使用等。
开发流程
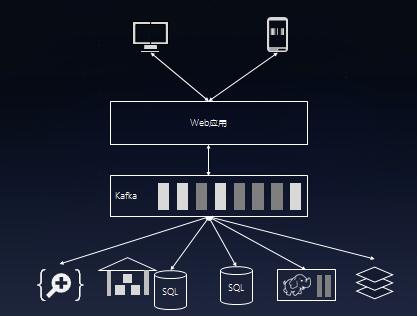
架构搭建
项目采用 Kafka 集群架构,Kafka能够提供消息队列,让生产者往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。
但是,Kafka不仅仅是一套传统的消息总线,本质上Kafka是 分布式的流数据平台,因为以下特性而著名:
- 提供Pub/Sub方式的海量消息处理。
- 以高容错的方式存储海量数据流。
- 保证数据流的顺序。
生产者模拟数据
有了Kafka的存在,我们可以编写程序mock出模拟数据,这里我们只需要模拟用户ID,用户打分和对应的商品ID,利用一个线程池分别模拟数据,模拟出的数据作为生产者产出到我们的虚拟机上的Kafka集群中。(因为没有数据,同时我们也模拟出了用来训练模型的数据)
这一步注意需要提前在Kafka集群上建好topic:
kafka-topics.sh --create --partitions 3 --replication-factor 2 --topic rate --zookeeper node91:2181,node92:2181,node93:2181

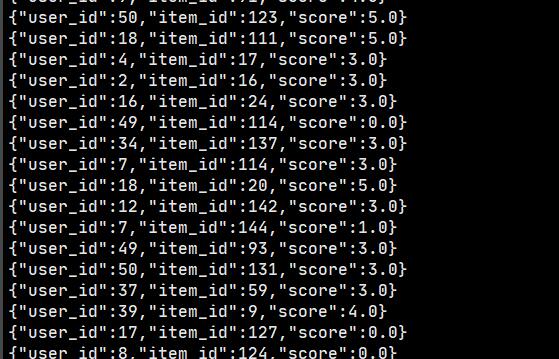
这里在模拟出数据了之后可以模拟消费者查看是否能够拉取到数据:
kafka-console-consumer.sh --bootstrap-server node91:9092,node92:9092,node93:9092 --topic rate --from-beginning
效果如图:
训练模型
在下一步之前,我们可以通过之前模拟出的训练集,使用MLlib训练ALS模型并保存,这里我将模型保存在项目文件中,并将模型的地址保存在redis中。
将80%的模拟数据作为训练集,20%的数据作为测试集。(因为数据本身也是随机模拟,没有采用交叉验证)
利用模型实时推荐
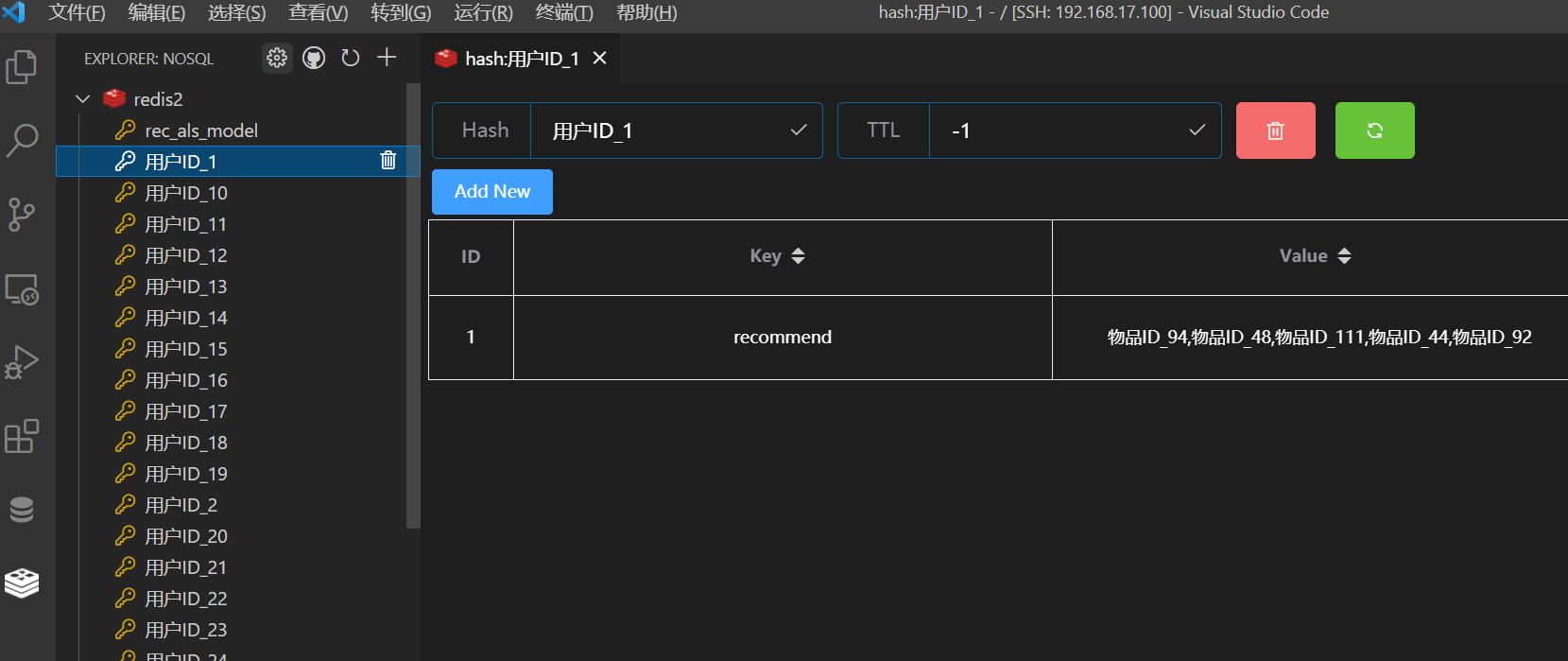
之后便可以在SparkStreaming中作为Kafka的消费者,对模拟出的每一个用户进行商品推荐了。推荐的结果可以按照需求存储,这里放入redis。
项目后期加入git仓库,代码较草率,轻喷。