

🧊foril







🧊foril
Attention 以及 Transformer
2017 年,Google 提出了一种新的神经网络架构 Transformer,它在机器翻译任务上取得了很好的效果。Transformer 的核心是 Attention 机制,它在 NLP 领域有着广泛的应用。在阅读了一些相关论文之后,本文尝试对 Transformer 以及 Attention 机制进行一些总结。
Attention 机制
Attention 机制最早是在 2014 年的一篇论文 Neural Machine Translation by Jointly Learning to Align and Translate 中提出的,它的目的是为了解决机器翻译中的长距离依赖问题。
学习长距离依赖性是许多序列转换任务中的一个关键挑战。影响学习这种依赖性的能力的一个关键因素是前向和后向信号在网络中必须经过的路径的长度。
Attention 机制最早从图像领域诞生,于 90 年代被提出。2014 年,Google Mind 团队发表论文 Recurrent Models of Visual Attention,让注意力机制开始火了起来,这篇论文是在 RNN 模型上使用了 Attention 机制来进行图像分类。
随后 2015 年 Bengio 的一篇论文 Neural Machine Translation by Jointly Learning to Align and Translate 首次将 Attention 机制应用到 NLP 领域(Bahdanau 注意力),采用 seq2seq 加 Attention 的模型架构进行机器翻译任务,之后本文也会简单对这种方式和 Transformer 进行对比。
然后就是 Attention 机制被广泛应用在基于 RNN、CNN 等神经网络模型的各种 NLP 任务中了。直到 2017 年,Google 机器翻译团队发表《Attention is All You Need》,完全抛弃了 RNN 和 CNN 等网络结构,大量使用 self-attention 机制来学习文本表示,仅采用 attention 机制来进行机器翻译任务,也就是大名鼎鼎的 Transformer 模型,引起了超大的反响。2018 年,谷歌团队提出 BERT 算法,其中最重要的部分也是来自于 Transformer。
所以要了解 Transformer 的具体结构,首先需要了解 Attention 机制。
Attention 的结构
我们可以简单的把 Attention 理解为一个黑盒子:
输入
- 一个 query
- 一组 key-value 对
输出
- 一个所有输入 value 的加权平均值(没错就是加权平均值,不是什么高大上的东西)
下面是一个简单的示意图:

类比我们人类的注意力,key 是多个输入的 非意志线索,代表一个物品本身的特点和突出性,value 是和 key 一一对应的,代表的是这样一个物品对你的实际感官输入。而 query 则是一个 意志线索,代表的是你的意志:对于这些输入你做选择的意愿,想要找到的是什么。
在 Attention 内部,会通过一个 汇聚函数(pooling function) 来计算出给每个 value 的权重,然后对所有 value 进行加权平均,得到最终的输出,当然输出的维度是和 value 的维度是一样的。
进一步来看汇聚函数的话,其实就是 一个输入是 query 和 key,输出一个对应权重作为结果的函数,这个函数一般都是用 softmax 函数来实现的,这样就可以保证所有的权重和为 1,也就是一个概率分布。所以汇聚函数可以进一步理解为

所以只要是一个输入 query、key、value,输出是一个常数的函数,就可以作为注意力汇聚函数 哪怕是不可训练的函数,比如平均汇聚。
Attention 的两种常见实现
上面说到了 Attention 机制的抽象理解,接下来我们就来看看 Attention 机制的两种常见实现方式:加性注意力和点积注意力。
additive attention
加性注意力,其实就是一个全连接层,禁用了偏置项,,,。
用 PyTorch 实现的话,就是这样的:
# torch self.W_k = nn.Linear(key_size, num_hiddens, bias=False) self.W_q = nn.Linear(query_size, num_hiddens, bias=False) self.w_v = nn.Linear(num_hiddens, 1, bias=False)
这里 和 其实可以合并成一个矩阵,这样的话加性注意力就是一个单层的全连接层,输入维度是 query_size + key_size,中间有一个隐藏层,输出维度是 1。
dot-product attention
点积注意力顾名思义就是通过两个向量的点积来计算权重,要求 query 和 key 有相同的长度 。
点积注意力没有可学习的参数,他背后的 intuition 是两个向量越相似,他们的得分越高(一个向量数字大的地方另一个也大,小的地方另一个也小,我认为是 排序不等式 的一种应用)。但是这样的话,当 query 和 key 的维度很大的时候,点积的结果会非常大,所以一般会除以 来缩小结果的范围(缩放点积注意力)。在 Transformer 中使用的正是这种缩放点积注意力。
虽然这两种实现方式在理论复杂性上相似,但点积注意力在实践中更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现,同时点积注意力还可以通过批量矩阵乘法来并行计算,比如这里在 个 query, 个 key-value 对的情况下,查询 ,键 ,值 ,那么点积注意力的输出就是
使用 PyTorch 实现的话,就是这样的:
torch.bmm(self.dropout(self.attention_weights), values)
Multi-head Attention
引入多头的目的是:给定相同的查询、键和值的集合时,希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖关系)。
这么做的效果在提出 Transformer 的论文中也有提到,发现单个注意力头不仅清楚地学习执行不同的任务,而且许多注意力头似乎表现出与句子的句法和语义结构相关的行为。
因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces) 可能是有益的。

具体实现时,就是把三个输入 投影 次,投影为 大小, 每次投影得到的形状一致,但投影矩阵权重不一致,学到不同子空间(说白了就是这里的全连接层权重都是不同的),投影的形状可以自己决定(Transformer 中也对不同参数进行了一些比较。),最后再将投影后得到的三部分输入送入 Attention 汇聚中,将得到的结果拼接起来,再经过一个全连接层,得到最终的输出。
Self Attention
在序列任务中,我们的输入是一组序列,比如文本序列,而 Attention 机制的输入是一个 query 和一组 key-value 对,所以我们需要让这组输入既当爹又当妈,既当 query 又当 key-value 对,这就是 Self Attention 的由来,即 查询、键和值来自同一组输入。Transformer 的核心就是将 Self Attention 机制应用到序列中,从而学习序列的表示。
Positional Encoding
由于 Self Attention 本身并不涉及序列的顺序信息,针对输入序列中的每个输入作为 query 时,输出都会考虑到其他所有的输入。
所以仅通过 Self Attention 处理的序列会失去时间或位置的信息。因此需要引入 位置编码,给模型提供关于序列中每个元素位置的信息。
我们可以用很多种方法嵌入这种位置信息,比如直接二进制表示序号等,只要提供了信息,不过信息效果怎么样就让他自己学去吧!
在 Transformer 的工作中采用的是正弦和余弦函数,位置编码具有与嵌入相同的维度 ,从而可以对这两个进行求和。位置编码的公式如下:
其中 是序列中元素的位置, 是维度的索引, 是嵌入的维度。
这么做的好处主要有:
- 可预测性:正弦和余弦函数是可预测的,这意味着模型可以轻松推断出未见过的位置编码。
- 相对位置信息:通过使用正弦和余弦波,相对位置的信息可以被模型学习到。即模型可以较容易地通过位置编码之间的差异来理解两个位置之间的距离。
- 频率混合:不同频率的波形有助于模型在多个尺度上学习信息。低频波形提供关于长距离关系的信息,而高频波形提供关于短距离关系的信息。
Transformer
理解了上面内容,接下来我们就来看看 Transformer 模型的结构。
Transformer 本质上也是针对序列任务做出的一种 Encoder-Decoder 模型架构,将不定长的输入序列总结为上下文信息传入 Decoder,这一点类似于传统 seq2seq 模型,但是 Transformer 完全抛弃了 RNN 和 CNN 结构,同时上下文信息会根据 Decoder 每个时间步的输出而有所不同,这一点会在之后和 Bahdanau Attention 进行对比。
主要特征
- Encoder-Decoder 模型
- 完全去除了 recurrence 和 convolutions 操作
- Encoder 和 Decoder 都堆叠(stack)了
- self-attention
- point-wise, fully connected layers
- 显著提高并行化程度
- 提高质量(新的 SOTA)
模型结构
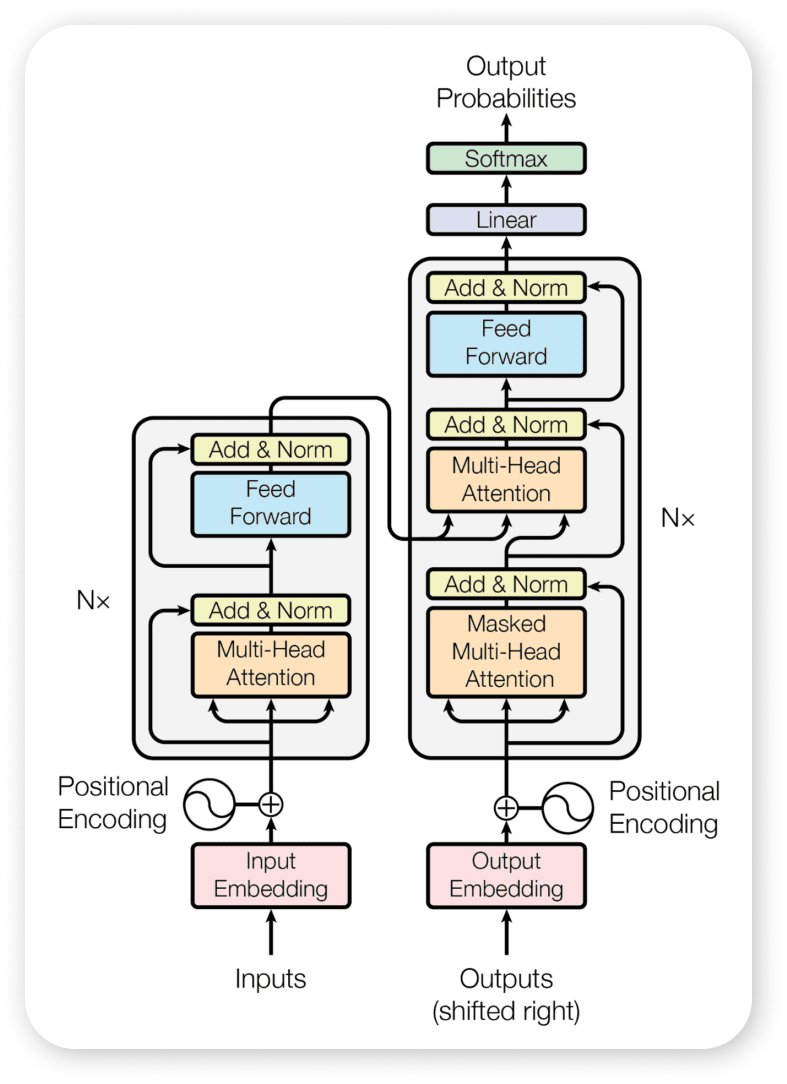
结合图片来看,Transformer 的 Encoder 和 Decoder 都是由多个相同的 block 堆叠而成。
这里所说的 堆叠(stack) 指的就是每一层的输出成为下一层的输入。第一层的输入是序列的嵌入表示,最后一层的输出被用于后续的任务
,这也要求每一层的输出和输入的维度是一致的。在 Transformer 模型中的所有子层以及嵌入层都会生成维度 的输出。
Transformer 中的任何层都不会改变其输入的形状,这一点对方便理解整个模型的运作方式至关重要。因为每一层都可以看做一个黑盒子,输入和输出的维度都是 ,所以整个模型的输入和输出都是 维度。
Encoder
Encoder 部分由 个相同的 block 堆叠而成,每个 block 由两个子层组成:
- 多头注意力机制
- 逐位置全连接前馈神经网络
第一个子层,取 个头,输入是经过嵌入的 维度的序列,在每一个 Self Attention 头中,既作为 query 又作为 key 和 value。三者都被投影到 维度,然后进行 次并行的 Self Attention 操作,最后将 个输出拼接起来得到 维度的输出,再经过一个 的线性变换,得到 维度的输出。
投影参数为
第二个子层是一个简单的神经网络,包含两个线性变换和一个 ReLU 激活函数,包括输入层、隐藏层和输出层,其中隐藏层的维度是 ,输入层和输出层的维度都是 ,隐藏层的激活函数是 ReLU。整个子层的计算可表示为:
position-wise 指的是对输入序列的每个位置(或时间步)独立应用相同的全连接层(但在不同的 block 中不同)。这意味着对于序列中的每个元素(无论其位置如何),都使用相同的全连接层进行处理。
以上两个子层都有一个 残差连接,然后再接一个 层规范化。
残差连接其实就是将输入直接加到输出上 ,体现在图中就是那条直接绕过子层连接到子层输出后的箭头,这样做的好处是可以防止梯度消失,同时也可以加速训练:梯度直接流向更深的层,可以直接向后传播而不会被太多修改或衰减;同时子层只需要学习输入到输出之间的增量改变,而不是完整的输出,这可能会让学习任务变得更加容易。
层规范化和 batch normalization 的目标相同,旨在减少不同层输入分布的变化,加速训练。但层规范化是基于特征维度进行规范化,将一层输出的不同特征进行规范化,得到均值为 0,方差为 1 的分布,而 batch normalization 是基于 batch 维度进行规范化,对一个 batch 的不同样本进行规范化。
层规范化有助于稳定深度网络的训练,通过确保每层的输入分布保持相对稳定,防止梯度消失和爆炸问题,这在训练深度 Transformer 模型时尤其重要。同时通过规范化层的输入,可以使得优化器更有效地工作,因为它不必应对不同层之间巨大的激活分布差异。这通常可以收敛更快。此外,有了层规范化,模型对学习率的选择不那么敏感。这是因为规范化减少了不同层激活分布的差异,使得更大范围的学习率都能有效工作。
Decoder
Transformer 的 Decoder 和整个 Encoder 结构基本一致,只是多一个额外的 Attention 机制 encoder-decoder attention 子层插在中间,在这个子层中,query 是 decoder 上一层的输出(由于输出和 query 的数量一致,所以每个 Decoder block 的输出和 Decoder 的输入一致),key-values 来自 Encoder 最后一层的输出,这个 attention 最后的输出作为上下文变量,这其实完全类比 seq2seq 模型中典型的编码器-解码器注意机制,可以让 Decoder 中每一步都关注到输入序列的所有位置。
此外,Decoder 中的 self-attention 也有一个额外的 mask,用于防止当前位置的输出依赖于后续位置的输出,这样可以保证模型在训练时只能看到当前位置之前的输出。这里其实也很好理解,因为在实际应用中,我们是不可能知道未来的信息的,所以在训练时也不应该让模型看到未来的信息。
数据流
以一个普通的机器翻译序列任务为例,模型的输入是序列经过嵌入后转化为 维度的向量序列 ,这个序列中每个元素经过线性变化加入位置编码后仍然保持 维度送入第一个 Encoder block,首先经过第一个多头注意力子层,向量序列既作为 Attention 机制的 query 又作为 key 和 value,三者都被投影到 维度,然后进行 次并行的 Self Attention 操作,最后将 个输出拼接起来得到 维度的输出,每个输入的 query 都对应一个 形状的输出,再经过一个 的线性变换,还是保持 维度的输出,此时输出形状仍为 ,接着经过第二个子层,输入和输出的维度都是 ,这时的输出作为整个 block 的输出,形状依旧是 ,传入下一个 block 作为输入,以此类推,直到最后一个 block,最后一个 block 的输出作为整个 Encoder 的输出,送入 Decoder。
在 Decoder 中也有类似的过程,首先第一个 block 的第一个输入是一个特殊的 <bos> 标记,输入的序列是
<bos> mask mask mask mask mask mask
这个序列经过嵌入后转化为 维度的向量序列(即,注意这里 和 Encoder 中的 可以不一致),每个元素经过线性变化加入位置编码后仍然保持 维度送入第一个 Decoder block,首先经过第一个子层,在这个子层经过多头注意力以及残差连接和层规范化后,输出保持 维不变。
接着经过 encoder-decoder attention 层,这个层的 query 是上一层的输出,key-values 来自 Encoder 最后一层的输出(它们的维度都是 ,所以这里输出的维度还是 ,和 Decoder 的输入形状一致,这个 attention 最后的输出作为上下文变量,送入最后一个子层,这个子层和 Encoder 中的第二个子层是一样的,输入和输出的维度都是 ,这时的输出作为整个 block 的输出,传入下一个 block 作为输入,以此类推,直到最后一个 block,最后一个 block 的输出作为整个 Decoder 的输出,这个输出向量的维度当然也是 ,
经过一个线性变换后,送入 softmax 函数,得到一个 概率分布,但在一个指定的 decoder step,我们只使用这个概率获取当前时间步的输出,所以对于时间步 ,我们取这个概率分布的切片 ,然后再通过 argmax 函数取出最大值的索引,这个索引就是当前时间步的输出,然后将这个输出作为下一个时间步的输入,以此类推,直到遇到 <eos> 标记,这时 Decoder 的输出就是整个模型的输出。
假设第一个时间步的输出是 Consider,那么下一个时间步的输入序列就是
<bos> Consider mask mask mask mask mask
这个输入再经过一次 Decoder 的解码,经过 softmax 之后也得到一个概率分布,然后将这个概率分布作为下一个时间步的输入,以此类推,直到遇到 <eos> 标记,这时 Decoder 的输出就是整个模型的输出。
<bos> Consider the following text as an example of how the Transformer works. <eos>
也就是说在整个 infer 的过程中,对于一个输入,Encoder (也就是图片的左半部分)只会计算一次,而 Decoder (图片的右半部分)会计算多次(autoregressive manner),直到遇到 <eos> 标记,这时 Decoder 的输出就是整个模型的输出。
这里的理解是基于我个人的理解,可能有些地方理解的不对,欢迎指正。
和 Bahdanau Attention 的对比
上面说到了 Bahdanau 注意力采用 seq2seq 加 Attention 的模型架构进行机器翻译任务。个人感觉 Transformer 的结构和 Bahdanau Attention 的结构非常相似,所以在这里进行一个对比。
Bahdanau Attention 也是一个 seq2seq 模型,它的 Encoder 和 Decoder 都是 RNN。
在下面这个传统的 Encoder-Decoder 模型,Encoder 最后输出的隐状态作为上下文变量,在 Decoder 中的每一步都会作为输入,这样 Decoder 中的每一步都会关注到 Encoder 中的所有位置。

但这样的局限就是,Decoder 所有位置收到的上下文信息都是完全相同的。然而,并非所有输入(源)词元都对解码某个词元有用。
Bahdanau Attention 正是解决了这样一个问题,它在每个时间步都会计算一个上下文变量,这个上下文变量是 Encoder 输出的上下文变量的加权平均,这个加权平均正是通过 Attention 机制计算得到的,query 是前一个 Decoder 的输出,key-values 都来自 Encoder 最后一层的输出(原本的上下文变量),这个 attention 最后的输出作为上下文变量,这样 Decoder 中的每一步都会关注到 Encoder 中的所有位置,但是每一步相对关注的重点是不同的,这样就可以解决上面提到的问题。
Bahdanau Attention 的结构如下图所示:

从这个图片也可以看出,Bahdanau Attention 的结构和 Transformer 的结构非常相似,只是 Transformer 中堆叠的 block 没有采用 RNN,而是采用了 Self Attention 和全连接层。