

🧊foril







🧊foril
Raft 协议详解
Consensus Algorithm 是分布式系统一个比较流行的话题,其主要目的就是想在多个节点间达成一个对数据状态的共识,这几天为了完成分布式系统的作业,去听了一下 MIT 6.824: Distributed Systems 对于这方面内容的讲解,觉得很有意思,下文对自己的理解和学习过程做一个简单的记录以便之后回顾。这里有一个简单的 动画演示 可以在开始之前有初步的理解,详细的内容可以参考这篇 论文。
A consensus algorithm is a process in computer science used to achieve agreement on a single data value among distributed processes or systems
——Wikipedia
什么是 Raft
目前的许多 replicated system 中(GFS、MapReduce 等)都存在 “单点故障” 的问题,其原因是为了防止在 replicated state machine 中产生 split-brain 问题,即多个 leader 对数据产生分歧(如下文所说,Raft 使用 大多数原则 来解决这个问题)。一些 Consensus Algorithm 的产生就是为了进一步压缩宕机的时间。很长一段时间中 Paxos 都占据了这个领域的主导,但由于其理解难度很大,实际实现复杂,导致很多真正的应用都或多或少存在一些不同,因此 Raft 诞生了,他在保证安全性以及基本性能的要求下,算法更为简洁易懂,更适于教学以及实际应用实现。只要大多数机器在正常运行,就可以保证整个协议始终正常运行(五台机器可以忍受两台宕机)。
举例来说,假如多个键值对服务器(state machine replication)需要对 client 的操作进行持久化存储,每个服务器下层都运行着 Raft 协议以保证数据的安全性,操作到达服务器后发送到下层的 Raft,由 Raft 决定执行时机和操作是否被提交。
state machine replication (SMR) or state machine approach is a general method for implementing a fault-tolerant service by replicating servers and coordinating client interactions with server replicas.
——Wikipedia
Raft 的组成
Raft 由三部分重要内容组成:
- Leader Election
- Log Replication
- Safety
Leader Election
每个机器有三种状态,即:
- Follower
- Candidate
- Leader
当一个 Leader 失联时,必须选出新的 Leader。
Leader 每隔一段时间就会向其他成员发送 心跳 以巩固地位,收到心跳的成员重置自己的定时器,一旦某位成员的定时器过期,就会从 Follower 变成 Candidate,向其他成员发送 选举请求(VoteRequest),一旦有多于半数的通过(当然自己也通过),就会成为新的 Leader,每个机器都会记得自己是否已经在这个任期内投过票,是否是投给这个竞选者。 如果在等待投票结果的过程中竞选者收到一个来自 Leader 的 claim,如果这个Leader 的届数大于等于自己当前竞选的届数,那么他就主动放弃,变回 Follower。
这里要注意的原则是每一个 任期(Term)都只有一个 Leader,并且不会有任何人有异议(因为一个机器要想成为 Leader 一定是获得了大多数认可,而另外的机器要想成为同一个任期内的 Leader,必定会至少有一个机器告诉他这个任期已经有已知的Leader 了,第几届总统是所有人都认可的,想要被所有人认可,你只能成为之后届的总统)。
Current terms are exchanged whenever servers communicate;
如果两个竞选者同时竞争,没人能获得大多数(Split Problem),那么他们都会放弃这个任期的竞选,自增任期并竞选下一个任期的 Leader,随机的过期间隔(比如 150ms-300ms)保证了他们不会无休止的同时竞争。
Log Replication
一旦成为 Leader,这台机器就开始服务 Client,接受其操作 LogEntry(包含操作具体内容以及当前任期)并放入自己的 LogEntries,之后 Leader 会在心跳包中加入 LogEntry 的信息并发送给其他机器(心跳包的本质就是没有 payload 的 AppendEntries RPC 请求),当收到大部分机器收到日志并同步到自己的 Logs 的肯定后,就会把这个任务标记为 commit 并给 Client 回复,被 commit 的 Log 在自己的 LogEntries 的索引会在每个心跳包内被发送出去,其他机器收到后同步日志到指定索引并执行。
由 Leader 接受 Log Entry 并复制给其他机器(Strong Leader 要求其他机器强制听从 Leader)。
正常运行时,每一步 AppendEntries 都能得到积极的反馈,但如果出现了 Leader crash 的情况,那么日志就可能会不一致。这种情况下,想要恢复一致性,Leader 会维护一个和所有机器各自认同的最后一个 agreement 的索引。若机器因为在同一个索引的 term 不同而拒绝了一次 AppendEntries,Leader 会将对应这台机器的需要对比的索引减一并重新发送确认,直到找到最靠后的一条 agreement,之后 Leader 会把从这个 agreement 到最新的所有 Log 一并发送,获得 success 即更新成功。
在这种机制下,Leader 永远也不会 overwrite 自己的日志,做到了 Strong Leader 的要求。
Safety
Raft 想要保证的原则是:任何一个被任意机器应用了的操作,都不会有别的机器在同一个日志索引处应用不同的操作。
在这一部分,Raft 算法加入一下对于哪些机器会被选举为 Leader 的限制以保证安全性。
Election Restriction
如果一个机器收到一个选举申请,且自己的日志比竞选者的更新(up-to-date),那么他将会拒绝这个竞选者的申请,一旦申请被更新的机器拒绝,那么竞选者就会回到 Follower 状态,至少等待这个更新的机器过期并竞选。
比较日志更加 up-to-date 的规则:
- 存储的日志中最后一条谁的 term 大,谁就新(注意是日志最后一条的 term,不是保存的已知的最晚的 term,极其容易错)
- 如果日志中最后一条谁的 term 一样大,谁的日志更多,谁就新
Committing entries from previous terms
需要注意的是哪怕是已经保存在大多数机器上的日志也有可能被覆写,如下图所示,虽然已经在大部分机器上保存,但没来得及 commit 的日志也有可能被覆写。
 为了避免这种情况发生,Raft 不会通过计数之前任期的日志的拷贝数量来确定其是否被 commit,只通过计数当前任期的日志的拷贝数量来确定是否 commit。
为了避免这种情况发生,Raft 不会通过计数之前任期的日志的拷贝数量来确定其是否被 commit,只通过计数当前任期的日志的拷贝数量来确定是否 commit。
特性
- Strong Leader
一个 Leader 只会强迫其他节点同步自己的日志,绝对不会改变自己的日志。 - commit is commit
正如其定义,a commit is durable and will be eventually executed by all state machines。之前的index也间接commit - Log Matching Property
不同日志中两条具有相同的 index 和 term,那么他们存储相同的命令,且之前所有的命令都相同
接下来放上分布式系统提交的报告,可能和以上部分有所重复。
本次作业为实现 Raft 的基础部分,即 Leader Election 以及 Log replication。
第一部分——Leader Election
在这一部分中,需要完成多台 state machine 的启动,完成正常的选举,以及在出现网络分区等各种非正常情况下的协议健壮性。
简要分析
以下简单对 Raft 的 Leader Election 部分做一个分析。
每个机器有三种状态,即:
- Follower
- Candidate
- Leader
当一个 Leader 失联时,必须选出新的 Leader。
Leader 每隔一段时间就会向其他成员发送 心跳 以巩固地位,收到心跳的成员重置自己的定时器,一旦某位成员的定时器过期,就会从 Follower 变成 Candidate,向其他成员发送 选举请求(VoteRequest),一旦有多于半数的通过(当然自己也通过),就会成为新的 Leader,每个机器都会记得自己是否已经在这个任期内投过票,是否是投给这个竞选者。 如果在等待投票结果的过程中竞选者收到一个来自 Leader 的 claim,如果这个Leader 的届数大于等于自己当前竞选的届数,那么他就主动放弃,变回 Follower。
这里要注意的原则是每一个 任期(Term)都只有一个 Leader,并且不会有任何人有异议(因为一个机器要想成为 Leader 一定是获得了大多数认可,而另外的机器要想成为同一个任期内的 Leader,必定会至少有一个机器告诉他这个任期已经有已知的Leader 了,第几届总统是所有人都认可的,想要被所有人认可,你只能成为之后届的总统)。
Current terms are exchanged whenever servers communicate;
如果两个竞选者同时竞争,没人能获得大多数(Split Problem),那么他们都会放弃这个任期的竞选,自增任期并竞选下一个任期的 Leader,随机的过期间隔(比如 150ms-300ms)保证了他们不会无休止的同时竞争。
数据结构设计
参考论文 Figure. 2,设计如下数据结果(AppendEntries相关数据结构将在下一章节介绍):
type LogEntry struct { Term int Command interface{} } // enum type for server state const ( Follower = 1 Candidate = 2 Leader = 3 ) // Raft // A Go object implementing a single Raft peer. type Raft struct { mu sync.Mutex peers []*labrpc.ClientEnd persister *Persister me int // index into peers[] // Your data here. // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain. // all servers' persistent staate currentTerm int // last term ever seen votedFor int // null if none log []LogEntry // all servers' volatile state commitIndex int lastApplied int // leader's volatile state nextIndex []int matchIndex []int timeout time.Duration timer *time.Timer state int // enum: Follower, Candidate or Leader ballot int applyCh chan ApplyMsg } // RequestVoteArgs // example RequestVote RPC arguments structure. type RequestVoteArgs struct { // Your data here. Term int // candidate's term CandidateId int // candidate requesting vote LastLogIndex int // index of candidate's last log entry LastLogTerm int // term of candidate's last log entry (decides whether up-to-date, rather than term does) } // RequestVoteReply // example RequestVote RPC reply structure. type RequestVoteReply struct { // Your data here. Term int // currentTerm, for candidate to update VoteGranted bool }
Raft 结构体代表 Raft 协议中的一个 State Machine 下运行的协议(举例来说,假如多个键值对服务器需要对 client 的操作进行持久化存储,每个服务器下层都运行着 Raft 协议以保证数据的安全性,操作到达服务器后发送到下层的 Raft,由 Raft 决定执行时机和操作是否被提交。
其中值得注意的内容包括:
currentTerm,其记录当前这台 server 见过的最新一个 term,如上文我所提到的,server 在 RPC 交换时都会进行比对,已获得尽可能新的 term。commitIndex,当前这台机器已经提交的 command id,在 Raft 中,一个 commit 就是一次绝对的提交,只要被提交的LogEntry 一定最终都会被所有的状态机执行,而且一个 LogEntry 的执行可以间接导致其之前所有的索引的日志全部提交。a commit is durable and will be eventually executed by all state machines.
lastApplied,当前状态机已经应用的 command,用于和commitIndex比对以确保所有被提交的日志都被执行(但这里我也不太明白为什么他是一个易失的属性?如果丢失了不会导致多次执行吗?)。nextIndex,如果当前状态机是 Leader,则需要维护长度为所有 peers 数量的数组,记录下一次要发给对应机器的日志索引。matchIndex,如果当前状态机是 Leader,则需要维护长度为所有 peers 数量的数组,记录可以当前所有机器确定和自己的 LogEntry 一致的日志索引(在 Raft 中的 Leader 是一个 Strong Leader 的概念,也就是说除了新增日志,一个 Leader 绝对不会修改自己的日志,而是强迫其他机器同步自己的日志)。
RequestVoteArgs 中需要注意的是 LastLogTerm,在 Raft 的投票中,为了保证一个能够当选的 candidate 至少包含所有已经提交的日志,所有机器只会向比自己记录的日志更新(at least as up-to-date)的 candidate 投同意票(用大多数原则解决 Split-Brain 问题),而在比较过程中,利用的就是当前存储的最后一条日志的 term 和索引大小,这里容易错的就是比较 currentTerm 而不是 LastLogTerm,实际上 currentTerm 是用于交换以保证 one Term, one Leader 的。此外,这个比较过程还利用了 Log Matching Property,即不同的状态机日志中两条具有相同的 index 和 term 的日志存储相同的命令,且之前所有的命令都相同。
关键函数
接下来给出几个关键函数的签名及其作用注释,具体代码见作业附件。
// refresh timer func (rf *Raft) tick() // RequestVote // RequestVote RPC handler. func (rf *Raft) RequestVote(args RequestVoteArgs, reply *RequestVoteReply) // if incoming RequestVote is fresher than oneself func (rf *Raft) incomingFresher(args RequestVoteArgs) bool // handle when received RequestVoteReply func (rf *Raft) handleVoteResult(reply RequestVoteReply) // what to do for a server when timeout func (rf *Raft) timeoutCallback() // first become Leader and continue sending heart beat func (rf *Raft) stepUpCallback() // AppendEntries handler // AppendEntries func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) // server(probably leader) receiving replies from handleAppendEntries func (rf *Raft) handleAppendEntriesResult(reply AppendEntriesReply, nodeId int) // send AppendEntry to certain server func (rf *Raft) sendAppendEntry2Certain(nodeId int)
具体函数的作用都已经在注释上进行说明,接下来详细说一下几个函数的调用关系。
一个服务器被 Make 出来后就会开始随机计时器(本项目按照论文实现为150-300ms),如果超时(在 tick 中),那么会触发 timeoutCallBack,这个回调函数会根据服务器的身份进行不同判断,Leader 直接重置计时器,而其他身份则会变为 Candidate 并发起投票(首先投自己一票),这里使用 goroutine 并行调用 sendRequestVote 以提高效率,要注意这里使用一个函数来方便每次启动一个新的 goroutine,如果不使用函数来拷贝一份每一个 server 的 id,多个 goroutine 可能会使用同一个变量值导致错误发生,这里一定要注意。
当收到 reply 调用 handleVoteResult 时,若收到的 term 比自己的新,则变回 Follower 身份并更新计时器,若收到同意且当前自己仍然是 Leader 身份(也是易错点),则判断自己得到的选票数量是否已经超过半数,超过半数则调用 stepUpCallback 上位并定时向其他机器发送心跳包。
在 stepUpCallback 中,首先初始化自己作为 Leader 的 nextIndex 以及 mactchIndex,然后循环判断在自己仍然是 Leader 的情况下,像所有机器发送心跳包并 sleep 一定间隔时间(本次实现设置为 100ms)。
sendAppendEntry2Certain 负责向指定服务器发送心跳包,在本章节中不需要 payload,只需要发送一个空心跳包包含自己的 Leader 信息即可。具体内容在下一章讨论。
剩下有关 AppendEntries 函数会在下一章详细解释。
这里不得不感叹一句,在实现的过程中 debug 真是一件痛苦的事情,有很多非常容易出错的情况,具体可以看代码注释,列出了一些易错点。
即便在网络通信可靠情况下,一个可扩展的分布式系统的共识问题通用解法的下限是——没有下限(无解)
第二部分——Log Replication
在这一部分,需要完成从 Leader 到其他 server 的日志同步要求(因为日志的流动是单向的,只能从 Leader 到其他 server)。
一旦成为 Leader,这台机器就开始服务 client,接受其command,包装至 LogEntry(包含当前 term)并放入自己的 LogEntries,之后 Leader 会在心跳包中加入 LogEntry 并发送给其他机器(心跳包的本质就是没有 payload 的 AppendEntries RPC 请求,这里比较复杂的是可能发送多条 LogEntry 以提高同步效率),当收到大部分机器收到日志并同步到自己的 Logs 的肯定后,Leader 就会把这个任务标记为 commit 并给 client 回复,被 commit 的 Log 在自己的 LogEntries 的索引会在每个心跳包内被发送出去,其他机器收到后同步日志到指定索引并执行。
由 Leader 接受 Log Entry 并复制给其他机器。
正常运行时,每一步 AppendEntries 都能得到积极的反馈,但如果出现了 Leader crash 的情况,那么日志就可能会不一致。这种情况下,想要恢复一致性,Leader 会维护一个和所有机器各自认同的最后一个 agreement 的索引。若机器因为在同一个索引的 term 不同而拒绝了一次 AppendEntries,Leader 会将对应这台机器的需要对比的索引减一并重新发送确认,直到找到最靠后的一条 agreement,之后 Leader 会把从这个 agreement 到最新的所有 Log 一并发送,获得 success 即更新成功,Leader 会更新下次发给该机器的索引。在这种机制下,就可以保证 Leader 永远也不会 overwrite 自己的日志。
数据结构设计
在第二部分中需要用到的数据结构如下:
type AppendEntriesArgs struct { Term int LeaderId int PrevLogIndex int PrevLogTerm int Entries []LogEntry LeaderCommit int } type AppendEntriesReply struct { Term int Success bool }
这里 prevLogIndex 和 prevLogTerm 是由 Leader 针对每一台机器的 nextIndex 发送的 Entries 中的第一条的在自己的日志里前一条的索引(好像有点绕,实际上也就是需要这台机器在收到这次的心跳包时需要比对自己对应索引是否一致的 term,因为之前说到的 Log Matching Property 保证了两条具有相同的 index 和 term 的日志就是同一条日志)。
关键函数
这里列出第二部分用到的几个关键函数的签名及其作用注释,具体代码见作业附件。
// AppendEntries handler // AppendEntries func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) // server(probably leader) receiving replies from handleAppendEntries func (rf *Raft) handleAppendEntriesResult(reply AppendEntriesReply, nodeId int) // send AppendEntry to certain server func (rf *Raft) sendAppendEntry2Certain(nodeId int) // apply uncommitted commands by comparing lastApplied and commitIndex of oneself func (rf *Raft) refreshCommits()
当一个服务器接收到 AppendEntries 信息时,通过 AppendEntries 进行处理,如果收到的声称为 Leader 的节点的 term 比自己还低,那么拒绝;否则更新自己的状态为 Follower(这里又是易错点,如果原来的一个 Leader 宕机了一段时间,苏醒后发现自己过时了就应该退位),并且如果自己的日志没有收到的需要比较的索引那么长或者 term 不匹配,则返回 false,要求 Leader 更新下一次发送的索引,知道找到最近的一个匹配。如果自己之前没有日志或是日志成功匹配,则添加 Leader 传来的所有日志,有必要的话更新提交的索引,并在 refreshCommits 中应用还未应用但已经提交的日志。
演示
通过 persist 前所有测试。
总结
Consensus Algorithm 是分布式系统一个比较有趣的话题,其主要目的就是想在多个节点间达成一个对数据状态的共识,这几天为了完成分布式系统的作业,也去听了一下 MIT 6.824: Distributed Systems 对于这方面内容的讲解,觉得很有意思,写下这篇报告,也是对自己的理解和学习过程做一个简单的记录以便之后回顾。
TODO
一些有意思的情况
论文中图六和图七有一些有意思且非常容易出错的情况,在 MIT 第一次 Raft 课程中最后同学们的讨论以及第二次老师的解答都可以参考,这里先不详细说明(最近考试太多),有机会再做补充。
简单记录
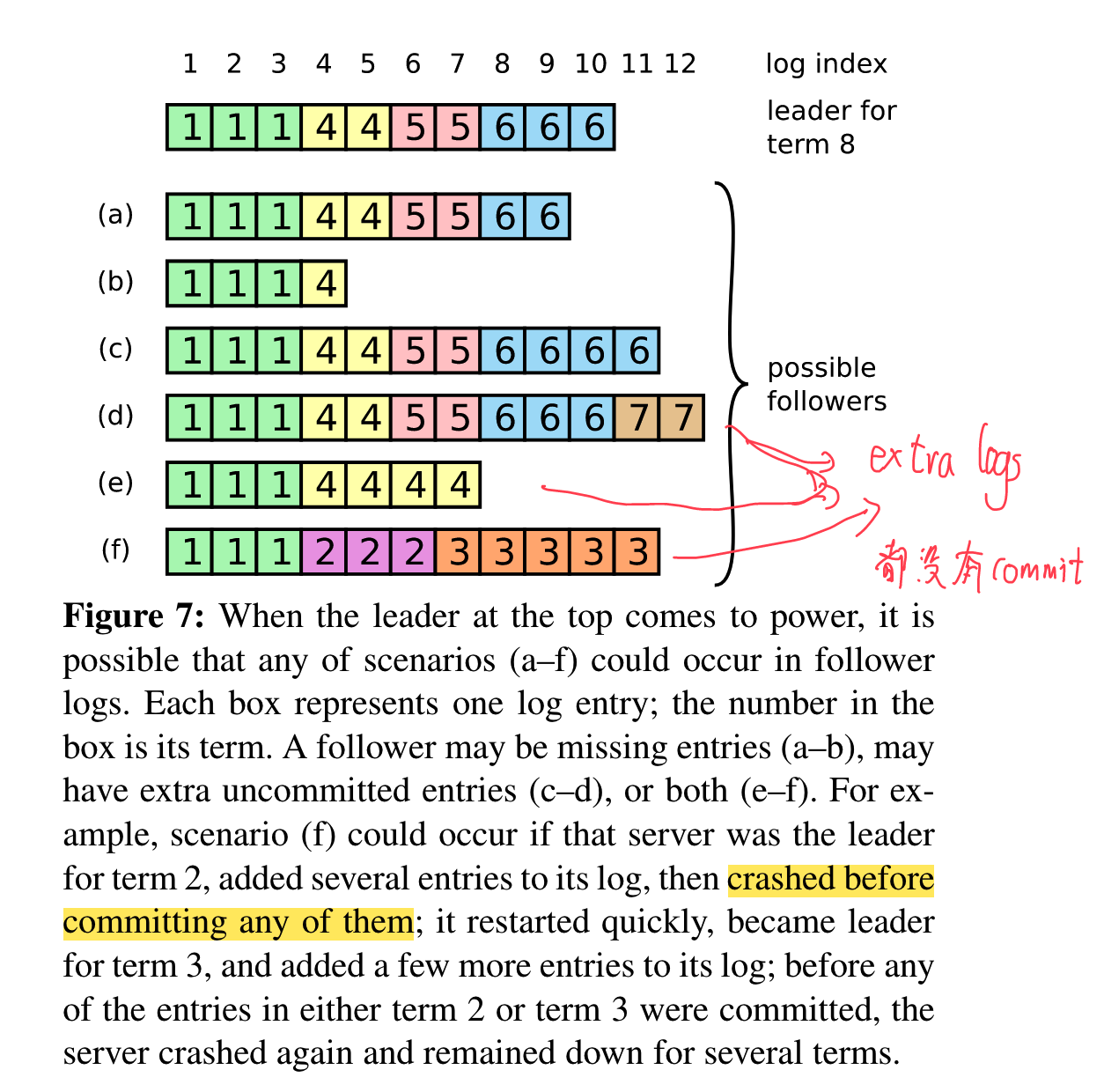
应该是?:d的term可能是任意高,比如他在term7(term7肯定是leader)后宕机,然后很快restart后又elect为term8 的 leader。 举例来说,既然他成为term8的leader,说明大多数server知道当前term为8,但比较比的是最后log的term,就是说,如果d还活着,他收到其他requestforvote都会拒绝(应为7比6、4、3都大),并让对方变成follower;但是如果d死了,c就可能变成新的term9的leader(哪怕他自己之前的term是6,他在申请成为leader交换时也能发现最新term是8并更新)
如果多个candidate竞争,没有任意一个获得大多数,那么所有candidate都会超时,然后自增竞选的term,重新请求投票,如果一直竞争,会永远重复下去(所以使用随机timeout解决)
怎么找到和leader相同的最后一个log,然后同步之后的log?
leader为这个follower存的nextindex自减并重试
只数当前term在大多数上才commit(之前的也间接commit)
If the leader’s term (included in its RPC) is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and returns to follower state. If the term in the RPC is smaller than the candidate’s current term, then the candidate rejects the RPC and continues in candidate state.