

🧊foril







🧊foril
利用 docker 配置深度学习环境
之前在配置深度学习环境时,就在考虑如果以后每次拿到一个新的计算资源(比如拿到系里新的计算资源) 都需要从头配置 Python、PyTorch 以及 Git 等工具的话,会不会很头疼,能不能用 Docker 来保存一个镜像,之后每次直接新建一个容器就可以直接使用。但是发现新建的容器似乎不能直接使用宿主机的 GPU,在查找资料后发现 Nvidia 官方针对这个问题有开发一系列工具包,这里简单记录一下使用的方式。
NVIDIA Container Toolkit
NVIDIA Container Toolkit 是一个开源软件包,他提供了一组容器的运行时库和工具,能够自动地配置容器使用宿主机的 GPU 资源。
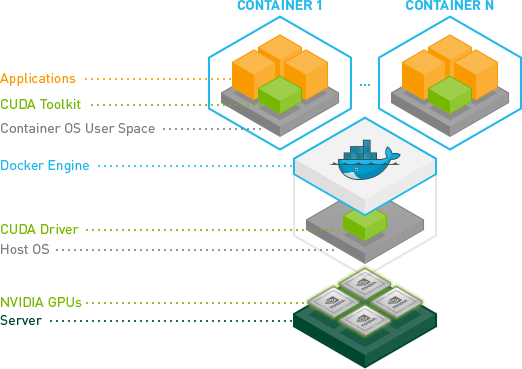
安装
在安装 Container Toolkit 前需要在你的 Linux 发行版上先安装 GPU 的驱动,不要求安装 CUDA Toolkit,但需要安装 NVIDIA 驱动程序(CUDA Toolkit 包含 NVIDIA 驱动)。
接下来是我实际安装的主要步骤。
系统:Ubuntu 18.04
GPU:Tesla V100 * 2
显卡的驱动版本和 Docker 的版本都有一定的要求,具体参考 官方安装文档。
这里主要说明安装好 GPU 驱动和 Docker 后的步骤。
如果迁移自 nvidia-docker 1.0,请遵循 迁移指南 中的说明。
Step 1:Setting up NVIDIA Container Toolkit
设置包存储库和GPG key,就可以之后通过 apt-get 安装:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
接着更新 apt-get 地址:
sudo apt-get update
然后就可以安装 toolkit:
sudo apt-get install -y nvidia-container-toolkit
Step 2:配置 Docker 守护进程
配置 Docker Daemon 以识别 NVIDIA 容器运行时:
sudo nvidia-ctk runtime configure --runtime=docker
Step 3:重启 Docker 守护进程完成安装
设置默认运行时后,重新启动 Docker 守护进程以完成安装:
sudo systemctl restart docker
现在,就可以启动一个容器看看是不是能够使用到 GPU 了!
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
在实际使用中,只需要我拉取一个 gpu 版本的 pytorch 镜像,就可以直接启用所有 GPU 用于对应的容器。